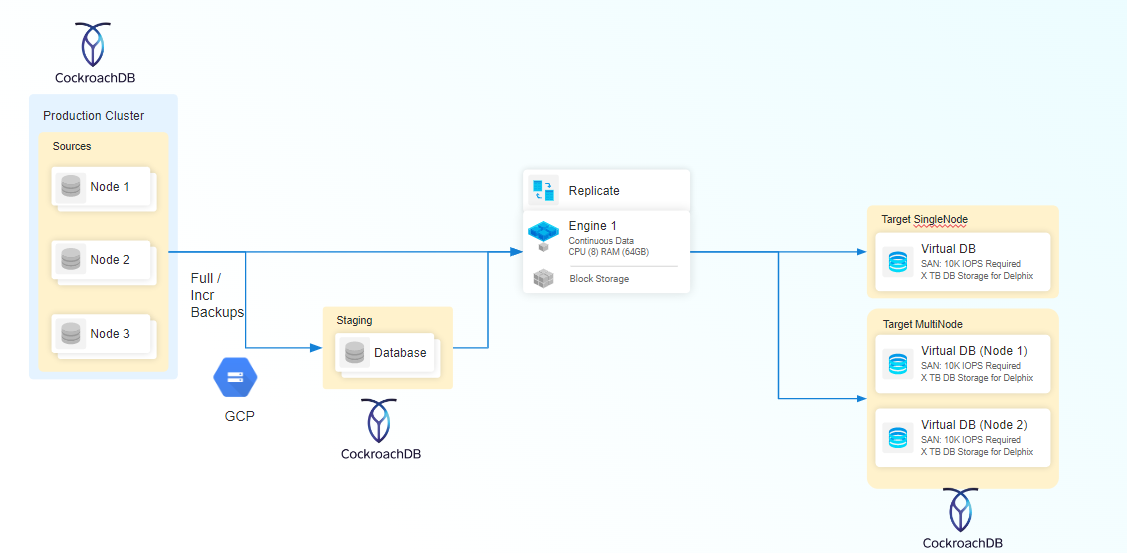
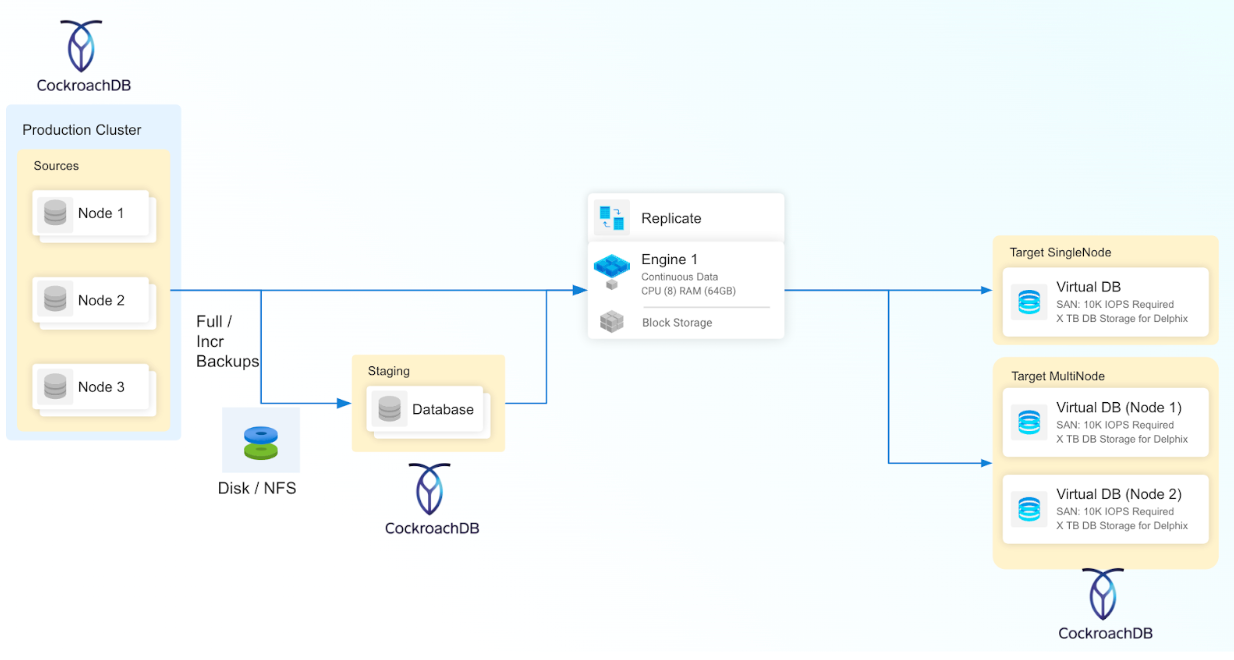
The Delphix CockroachDB virtualization solution uses a Staging Architecture Model. In this model, the source (production) database is copied to a staging environment. The staging environment’s database is ingested by the Delphix Continuous Data Engine, which then enables virtualized copies on a target environment.
The CockroachDB plugin leverages CockroachDB's built-in backup and restore procedures to virtualize the data source. You can use the BACKUP statements to efficiently backup the cockroach cluster and data to popular cloud services such as AWS S3 or NFS, and the RESTORE statement to efficiently restore schema and data as necessary. The CockroachDB restore process is capable of restoring from either a full backup or from a combination of a full backup with incremental backups.
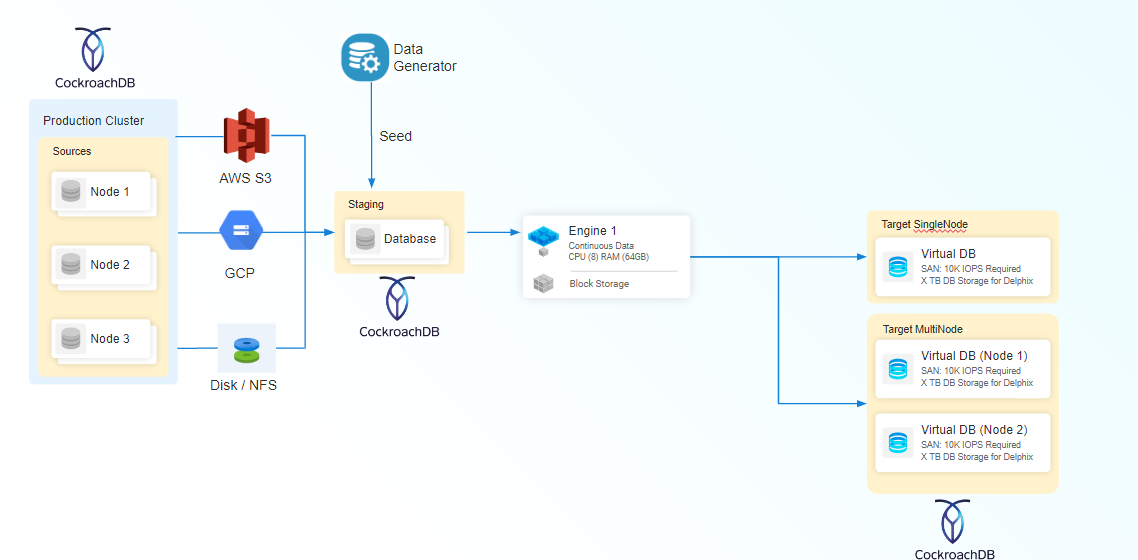
The CockroachDB connector supports the following ingestion mechanisms:
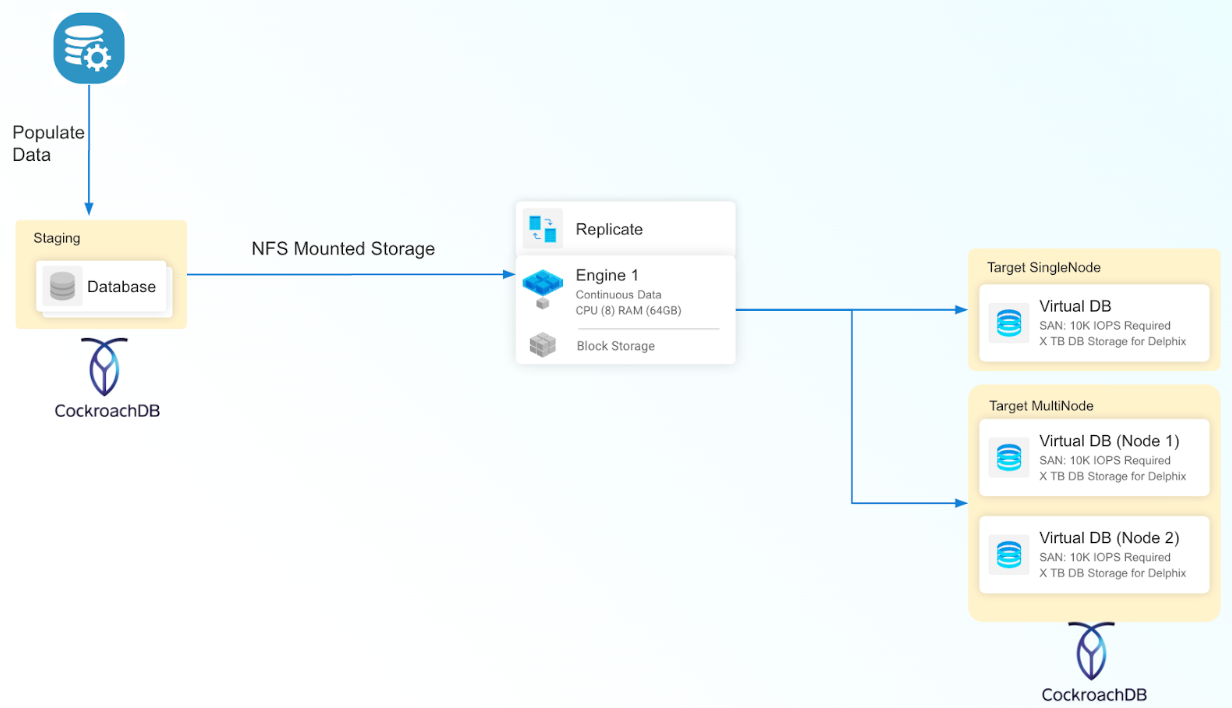
Seed
The Seed ingestion mechanism in the CockroachDB connector serves as a foundational approach for creating a seed database, allowing users to populate it with diverse data through various techniques such as built-in data generators, SQL statements, or the IMPORT command. This seed database serves as the initial dataset, providing a starting point for users to establish their CockroachDB environment.
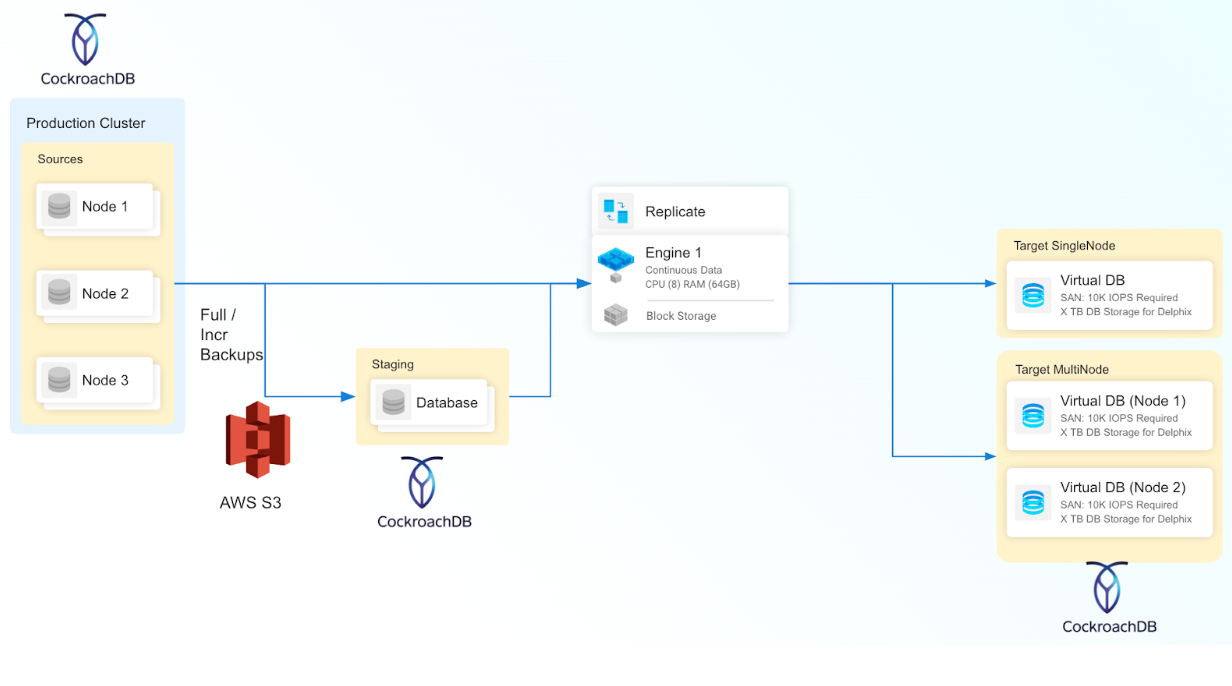
AWS S3 Backup
This ingestion type is generally used to create a staging database by utilizing backup files found within an AWS S3 location. This process facilitates the creation of a staging database through a zero touch production approach. Periodic backups stored on AWS S3 locations can be loaded to create a dSource timeflow.
Disk Backup
This ingestion type is generally used to create a staging database by utilizing backup files found within Disk/NFS locations which are accessible from the Staging host. This process facilitates the creation of a staging database through a zero touch production approach. Periodic backups stored on Disk/NFS locations can be loaded to create a dSource timeflow.
Google Cloud Platform (GCP)
This ingestion type is generally used to create a staging database by utilizing backup files found within a GCP bucket. This process facilitates the creation of a staging database through a zero touch production approach. Periodic backups stored on GCP bucket can be loaded to create a dSource timeflow.