
General architecture
Ingestion overview
Delphix Continuous Data Engine automatically delivers copies of data to developers and testers to enable high-quality, on-time application development while mitigating infrastructure costs.
These virtual data copies are full read-write capable database instances that use a small fraction of the storage resources that a normal database copy would require. This helps promote a seamless flow of updates and changes to your data in real-time.
In order to create virtual data copies, Delphix Continuous Data Engine must ingest a copy of the source database into persistent storage on the engine, to later be provisioned as one or more copies.
After a copy is ingested, an imperative step is to preserve its current state by taking a snapshot. Subsequently, generating a VDB by provisioning it from the ingested copy establishes a replica of the source database. This VDB can be further enhanced by allowing snapshots or bookmarks, facilitating the capture of its current state for future reference.
Implementing functionality to rewind the VDB to a previous state is crucial. This action allows you to navigate and revert to specific points in the VDB's history. A dSource must consistently reflect the most recent changes from the source database. To do so, you must enable the refreshing of the dSource, maintaining synchronization with the source data.
Furthermore, for a VDB to stay current, it can be refreshed by updating it with the latest changes from a new snapshot of the dSource. Lastly, perform cloning of a VDB to create a child VDB.
Ingestion is the important process by which a consistent, ready-to-run copy of the data is prepared and captured, and persisted as a Delphix snapshot in Delphix storage, so that it can be provisioned to virtual copies as Delphix vDB(s). Before beginning, it’s important to understand the recommended ways to ingest.
There are two architectural models by which Delphix performs ingestion:
Direct ingestion
Direct ingestion is an approach where the Delphix Continuous Data Engine is able to extract (directly from the true production source) the necessary information to reconstruct the source database and persist it into storage on the Delphix Continuous Data Engine. This direct methodology requires no intermediate host nor instance of the source database. The Delphix connector must interact directly with the true production source system to request the data to be persisted. There is no activity whatsoever on an intermediate staging host; instead the blocks are directly written to storage on the Delphix Continuous Data Engine.
The two primary examples of Direct ingestion are:
Unstructured files ingestion (does not require a connector).
Oracle database ingestion via direct integration with Oracle RMAN (Recovery MANager) utility.
For unstructured files ingestion, the Delphix Continuous Data Engine will connect directly to the true production source of the files and RSYNC them onto a filesystem in Delphix Storage.
Oracle database ingestion via RMAN integration is where the Oracle RMAN utility is able to ship the entire storage block map to Delphix when Delphix requests it, then later just the changed blocks since the previous ingestion (an incremental roll forward capability).
Staged ingestion
Staged ingestion dictates and expects reconstruction of the source database on an intermediate host (separate from the true source system) or instance of the source database. The intermediate platform is called Staging, and the persistent storage which backs the staging database is provided over the network by the Delphix Continuous Data Engine.
The majority of Delphix Continuous Data Connectors perform Staged ingestion.
Two common examples of Staged ingestion are:
Backups and logs.
Various forms of replication (physical or logical).
Backup and log ingestion is where database backups and transaction logs from a true production source database are recovered and rolled-forward on a staging host, where the persistent storage is provided by the Delphix Continuous Data Engine. The activity is completely independent and isolated from the true source database and system. This example of Staged ingestion requires zero communication between the Delphix solution, and the true production system, as long as the needed backups and logs are made accessible to the staging host.
Replication ingestion is where the staging host is configured as a replica to true production. Each DBMS system has its own specific facility and methodology for implementing replication. Typically some sort of direct communication is required to exist between the staging host and the true production source host.
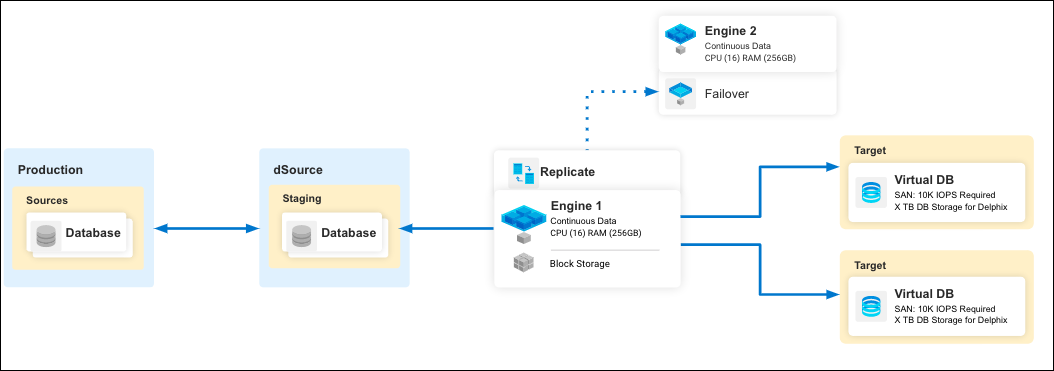
Staging Pull vs. Staging Push
As described above, Staged ingestion involves an intermediate environment that mounts Delphix storage over the network for persistent storage (rather than locally-attached, physical storage) upon which the source database is reconstructed or prepared.
There are two forms of Staged ingestion:
Staging Pull
Staging Push
The distinction between the two hinges on whether or not Delphix Continuous Data performs the steps to prepare the data contents in the staging dataset.
Staging Pull: Delphix Continuous Data performs the preparation and reconstruction (e.g. database restore/roll forward or replication configuration).
The process is entirely under the control of Delphix and cannot be modified nor substantially customized by the user. The benefit is that the heavy lifting to prepare the data on the staging host is automated and entirely taken care of by Delphix, simplifying the operational steps for the user. The downside is that the process is hard-coded and cannot be customized or modified, nor integrated with other third-party applications (like various Enterprise Backup solutions). This approach typically results in a logically identical copy of the pristine production data.
Staging Push: The user, outside of Delphix Continuous Data, performs the steps of data preparation and reconstruction.
The user can tailor and customize the process, integrate with third-party tools, and is free to create the data contents however they wish. This approach is wide-open and can be performed however the user prefers, as long as the outcome results in a valid dataset (as determined by the corresponding DBMS) at the time that a dSource snapshot is taken in Delphix Continuous Data.
This approach is infinitely more flexible, in exchange for increased responsibilities placed upon the user. This approach can produce logically identical contents of the pristine source data, but also offers flexibility to filter, modify, or reorganize the data so that it is not logically identical to the original source.
Provisioning
After the data source has been successfully ingested into Delphix Continuous Data Engine and represented internally as a dSource, it can be provisioned as a virtual database (VDB). VDBs are deployed onto a target environment and leverage the binaries and resources that are made available.
Once the VDB is running, a wide array of functionality is made available to it, such as refreshing it back to the latest dSource’s snapshot, snapshotting a new branch of the dataset, or sharing it with team members. Then, when no longer needed, the virtual database can be destroyed and resources are instantly reclaimed in the target environment. Delphix Continuous Data Engine’s virtualization capabilities drastically lower the effort required to manage datasets.
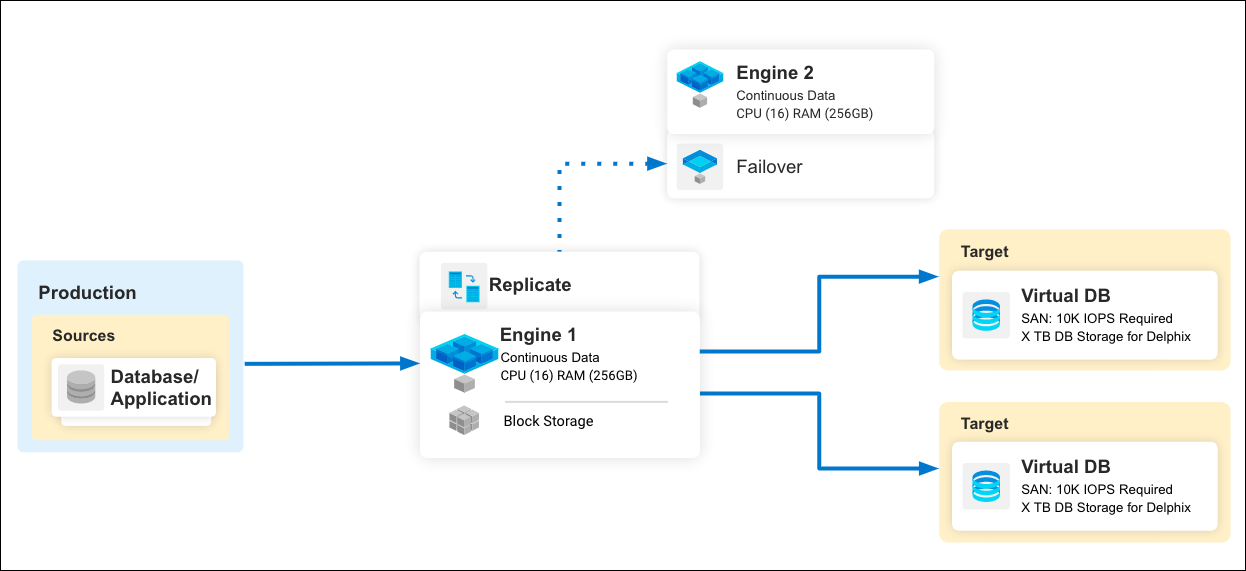
In advanced scenarios, virtual database management might be required to offload target environments or share datasets with other engines. For example, the migrate capability allows administrators to move the VDB from one target environment to another. This is particularly helpful if a target environment is overloaded or the end user is in a different region or zone.
Similarly, a virtual database can be copied to other engines through the process of Replication. In this scenario, the replica is a read-only virtual database in which other virtual databases can be provisioned from where the dSource is not directly available. This is valuable when combined with Delphix’s Continuous Compliance’s masking and production and non-production zones. In these scenarios, a masked virtual database is provisioned in production and then replicated over to the non-production zone to eliminate data leak risk. It is also broadly helpful to organize engines and limit access to certain datasets.