
Understanding data sources
A data source can be a database, an application, or a set of unstructured files. Engine Administrators configure the Delphix Engine to link to data sources, which pulls in the data of these sources. The Delphix Engine will periodically pull in new changes to the data, based on a specific policy. This, in turn, begins building a custom timeline for each data source. Additionally, the Delphix Engine can rapidly provision new data sources that are space-efficient copies, allowing users to work in parallel without impacting each other.
Understanding data templates
Data templates are the backbone of data containers. They are created by the Engine Administrator and consist of the data sources that users need in order to manage their data playground and their testing and/or development environments. Data templates serve as the parent for a set of data containers that the administrator assigns to users. Additionally, data templates enforce the boundaries for how data is shared. Data can only be shared directly with other users whose containers were created from the same parent data template.
Understanding data containers
A data container allows data users to access and manage their data in powerful ways. Their data can consist of application binaries, supporting information, and even the entire database(s) that underlie it.
A data container allows users to:
-
Undo any changes to their application data in seconds or minutes
-
Have immediate access to any version of their data over the course of their project
-
Share their data with other people on their team, without needing to relinquish control of their own container
-
Refresh their data from production data without waiting for an overworked DBA
A data container consists of one or more data sources, such as databases, application binaries, or other application data. The user controls the data made available by these data sources. Just like data sources in a template, changes that the user makes will be tracked, providing the user with their own data history.
The Data Container Interface lets users view the details and status of their data container and its associated data sources, as well as manipulating which data is in those sources. The Data Container Interface includes a section called the Data Container Report Panel, which displays details about each source, including the connection information needed to access it – for example, the java database connectivity (JDBC) string for a database. This connection of information is persistent and stable for the life of the data container, regardless of what data the resources are hosting.
Data flow
The Delphix Self-Service data flow diagram below demonstrates how a Delphix Self-Service data user accesses data sources. Data sources are connected to a Delphix Engine, which is controlled by the Engine Administrator. The Engine Administrator will connect all data sources that developers and quality assurance (QA) teams need to a data template. This data template acts as a parent source to create the data containers that the administrator will assign to data users. Data sources flow from the Delphix Engine into a data template and downstream into a data container, where a data user or users will use the data sources to complete tasks. The data container acts as a self-contained testing environment and playground for the data user. Additionally, data users are able to set, bookmark, and share data points in their container with other data users of other data containers, as long as all the data containers were created from the same parent data template.
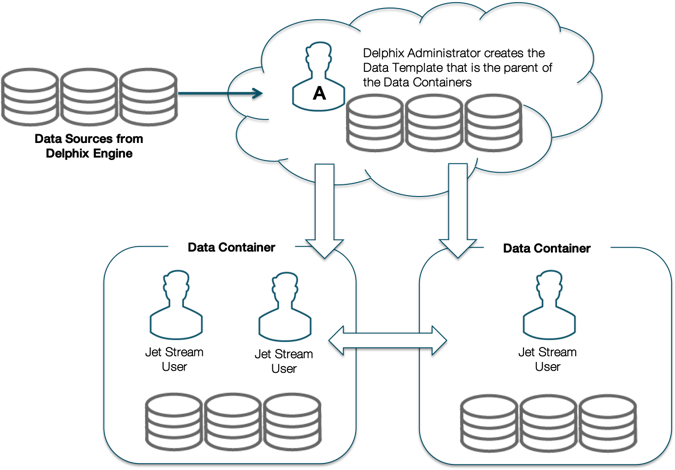
Data Flow
Understanding branches
You can organize data in the data container into task-specific groupings, called "branches." For example, you can use a branch to group all the data you have used while addressing a particular bug, testing a new feature in an application, or exploring a business analytics scenario. By default, Delphix Self-Service automatically creates the first branch of source data for you when you login for the first time. You can view the default branch and any additional branches that you create over time by clicking the Branch tab. Additionally, to the right of the default branch, you will see an interconnected branch timeline unique to whichever branch is currently active. The illustration below displays both the default branch in the Branch tab of the Data Container View Panel and the default branch timeline.

Branch Tab

Branch View Panel and Branch Timeline
A branch is used to track a logical task and contains a timeline of the historical data for that task. One branch is the "active" branch, which means that it is the branch that is currently being updated with new data from the data sources. At any time, you can change which branch is active and thus change which data is in the associated data sources.