
Introduction
The Elastic Data product uses object storage to provide a cost-effective and flexible medium for storing an engine’s data without compromising performance for most workloads. From version 15.0.0.0 and later, it is possible for a sysadmin to migrate an engine’s storage pool residing in local block storage to object storage backends, in-place and with no downtime.
If your kernel version is below 15.0, you cannot perform an in-place block-to-object storage migration. To enable this feature, you must first run a full upgrade to version 15.0 or higher.
Prerequisites
The migration process requires:
-
An object storage endpoint with access credentials where the data from the block-based storage pool will be migrated to. The object storage backend needs to be supported by the Continuous Data Engine (e.g. AWS S3, Azure Blob, OCI Object Storage, and various on-prem solutions).
-
One or more high performance block device(s), to be used as an object storage cache during and after the migration is finalized. Disks that are currently configured in your Continuous Data Engine cannot be used for this purpose.
Limitations
In-place migration is an irreversible operation. Once started, it cannot be stopped, nor paused, nor reversed.
Additionally, during the migration process, sysadmins are not able to add or remove block devices for data storage. Cache device removal is not allowed either while the migration is in progress. Cache device additions are allowed at any time (e.g. to improve performance during or after the migration).
Other methods of migration
An alternative to this feature would be replicating data to a new engine that was created with an object storage-backed pool from the start. This approach has some potential drawbacks:
-
This migration path is not viable for engines that already use replication.
-
The process is complex and potentially error-prone. The sysadmin would need to: Create a new VM, start the replication, notify their users, update infrastructure to use the new VM, and finally delete the old VM.
-
Infrastructure requirements temporarily double. While transitioning, the sysadmin needs to use double the infrastructure that would normally be needed. This can be a tough requirement to meet when multiple product engines need to be migrated.
-
There is downtime involved. If the write-load of the transitioning VMs is high, sysadmins may need to plan some downtime for finalizing replication and switching users over to the new VM.
-
The process can be time-consuming. Multi-TB storage pools may take too long to migrate, as the network is involved in two places: replication and writes to the object storage. An in-place migration only involves the network when writing to the object storage.
Instructions
The following example walks through a migration in AWS for a storage pool migrating from EBS Volumes to S3. Please adjust the steps for your cloud platform accordingly.
-
Add one or more high-performance block device(s) to your engine from the cloud console or hypervisor to be used as a cache. In this example, two gp3 EBS Volumes have been added to a demo VM.
-
Login to the Delphix CLI as a sysadmin user.
-
Navigate to the storage/device directory with
cd storage/device. Typelsto list all devices currently detected by the VM and find the name of the block device you just added.ip-10-110-196-27> cd storage/device ip-10-110-196-27 storage device> ls Objects NAME BOOTDEVICE CONFIGURED SIZE EXPANDABLESIZE FRAGMENTATION ALLOCATING xvda true true 70GB 0B NA true xvdb false true 100GB 0B 54% true xvdc false true 100GB 0B 58% true xvdd - false 50GB - - - xvde - false 50GB - - -In the above sample, the devices just added stands out because they are the only non-configured ones;
xvddandxvde. -
Navigate to the /storage/migrate directory with
cd /storage/migrate/. Typestartto start the migration API form and (optionally)lsto list all fields that are required for submitting the migration job.ip-10-110-196-27 storage device> cd /storage/migrate/ ip-10-110-196-27 storage migrate> start ip-10-110-196-27 storage migrate start *> ls Properties type: BlobObjectStore accessCredentials: (unset) cacheDevices: (unset) configured: false container: (unset) endpoint: (unset) size: (unset) -
Set the correct
typeof object storage (in this caseS3ObjectStore) with thesetcommand:ip-10-110-196-27 storage migrate start *> set type=S3ObjectStore -
Set the access credential type and info (this can vary by hypervisor/cloud provider).
-
Using AWS instance profile authentication is simple and can be done with a single command:
ip-10-110-196-27 storage migrate start *> set accessCredentials.type=S3ObjectStoreAccessInstanceProfile -
If access key credentials are preferred, then the access ID and its respective key should be specified:
ip-10-110-196-27 storage migrate start *> set accessCredentials.type=S3ObjectStoreAccessKey ip-10-110-196-27 storage migrate start *> set accessCredentials.accessId=<redacted> ip-10-110-196-27 storage migrate start *> set accessCredentials.accessKey=<redacted>
-
-
Input the object storage’s endpoint and related info (the fields may vary based on the hypervisor/cloud provider object storage that you want to connect to):
ip-10-110-196-27 storage migrate start *> set endpoint=https://s3-us-west-2.amazonaws.com ip-10-110-196-27 storage migrate start *> set region=us-west-2 ip-10-110-196-27 storage migrate start *> set bucket=delphix-data ip-10-110-196-27 storage migrate start *> set size=500G
The size field is the storage quota that the sysadmin can use to limit the engine’s usage of the object storage backend. The sysadmin can change that value post-migration as needed if their storage requirements change.
-
Finally, set the cache to the new devices that were added in step one (see name of devices in step three):
ip-10-110-196-27 storage migrate start *> set cacheDevices=xvdd,xvde -
(Optional) Type
lsonce more to verify that all your info is entered correctly:ip-10-110-196-27 storage migrate start *> ls Properties type: S3ObjectStore (*) accessCredentials: type: S3ObjectStoreAccessKey (*) accessId: ******* (*) accessKey: ******** (*) bucket: delphix-data (*) cacheDevices: xvdd, xvde (*) configured: false endpoint: https://s3-us-west-2.amazonaws.com (*) region: us-west-2 (*) size: 50GB (*) -
Type
committo submit the migration job (warning, this is an irreversible operation - see Limitations section). If there is something wrong with the credentials, the connectivity of the VM, or any of the above parameters that you typed above, the command will fail and give a helpful message. Otherwise, if everything is correct, you will see the message below:ip-10-110-196-27 storage migrate start *> commit Dispatched job JOB-23 OBJECT_STORE_MIGRATE job started for "unknown". OBJECT_STORE_MIGRATE job for "unknown" completed successfully.The above means that the job submission was successful and it is running in the background.
There are a couple of ways to track the job’s progress. The easiest way is viewing the Actions Panel in the sysadmin UI (see Viewing actions status for more details).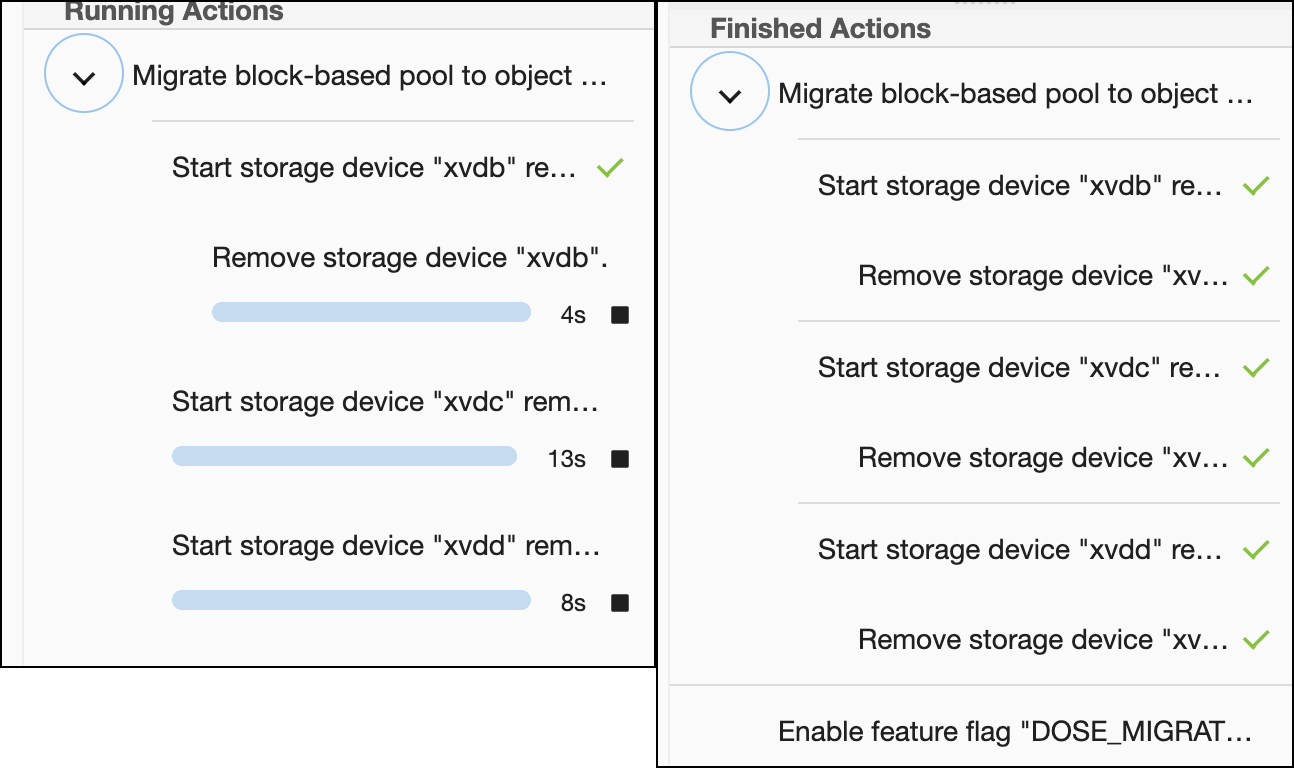
The other way is through the CLI by typingcd /storage/migrateand then runningls:ip-10-110-228-202 storage migrate> ls Properties type: ObjectStoreMigrationStatus mappingMemory: 0B startTime: 2023-08-25T23:48:03.077Z state: ACTIVE total: 20.13MB